RedTitan EscapeE may be used to recover textual information from most print file and document formats. An area of the page called a 'field' can be drawn on the screen. The textual content of any number of fields can be recovered and saved for later processing.
Some printer files, like inkjet driver output, or image formats like JPEG and TIF present special problems. Where the document was not created using fonts, the textual information may still be recovered using 'Optical Character Recognition'.
EscapeE uses RS2 script to interface with the TESSERACT OCR engine.Contents
If you intend to use OCR to process documents, it is important that the limitations of this process are understood. The character shapes used in printed text were not designed to make computer recognition easy, and very often, printing and scanning technologies can also cause surprising errors. e.g. (but not limited to)
Of course, scanning at low resolution or from poor originals can introduce further 'noise' related issues. Very few OCR systems are accurate with very small characters, floating accents, low contrast and punctuation. The very nature of the process makes proofreading difficult. The results may at first appear very good because the redundancy in a written language is sufficient for the human reader. If the results are intended for computer processing then it is important to try and build checking into the process. e.g. compute check digits in reference number, look up valid names and cross reference.
Ask RedTitan support for IDF licence permission. EscapeE OCR requires a minimum TESSERACT 3.01 to be installed as follows. {root} is the folder where ESCAPEE.EXE is installed. The minimum set may be downloaded from the tesseract OCR site. RedTitan uses a direct API and does not use the command line tools. To support a non-English language it is sufficient to download a single 'trained data' file. e.g. deu.traineddata contains the special characters (like umlauts) used in German text.
{root}\plugins\tesseract\tessdata\eng.cube.bigrams
{root}\plugins\tesseract\tessdata\eng.cube.fold
{root}\plugins\tesseract\tessdata\eng.cube.lm
{root}\plugins\tesseract\tessdata\eng.cube.nn
{root}\plugins\tesseract\tessdata\eng.cube.params
{root}\plugins\tesseract\tessdata\eng.cube.size
{root}\plugins\tesseract\tessdata\eng.cube.word-freq
{root}\plugins\tesseract\tessdata\eng.DangAmbigs
{root}\plugins\tesseract\tessdata\eng.freq-dawg
{root}\plugins\tesseract\tessdata\eng.inttemp
{root}\plugins\tesseract\tessdata\eng.normproto
{root}\plugins\tesseract\tessdata\eng.pffmtable
{root}\plugins\tesseract\tessdata\eng.tesseract_cube.nn
{root}\plugins\tesseract\tessdata\eng.traineddata
{root}\plugins\tesseract\tessdata\eng.unicharset
{root}\plugins\tesseract\tessdata\eng.user-words
{root}\plugins\tesseract\tessdata\eng.word-dawg
{root}\plugins\tesseract\tessdata\osd.traineddata
The following files must be present to provide the RedTitan technical interface.
{root}evaldial.exe RS2 scripting wizard
{root}\plugins\EVALUATE.EEP evaluate plugin - RS2 scripting API
{root}\plugins\tesseract\tess301.dll interface to tessercat OCR engine
Tesseract OCR uses a database that contains the recognition information for a number of glyphs. This information is derived from a process called 'training'. Target character shapes are compared to the database information and given a recognition 'confidence' value. The OCR engine is unaware of the positional context of a character shape but extended parameters may be used to give hints to the recognition system. e.g. the 'whitelist' parameter lists what characters may appear in the scanned graphic. A character that is not in the selected language set will not be recognised.
By default, all 'trained' characters are processed in the English(eng) set as follows.
| deu.traineddata | German |
| fra.traineddata | French |
| nld.traineddata | Netherlands |
| spa.traineddata | Spanish |
| ita.traineddata | Italian |
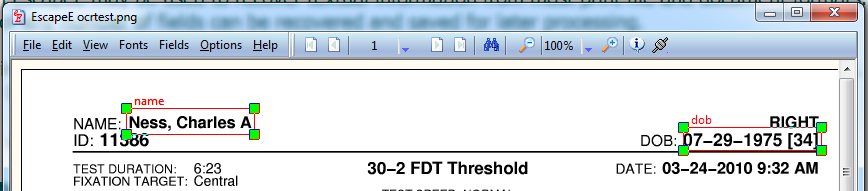
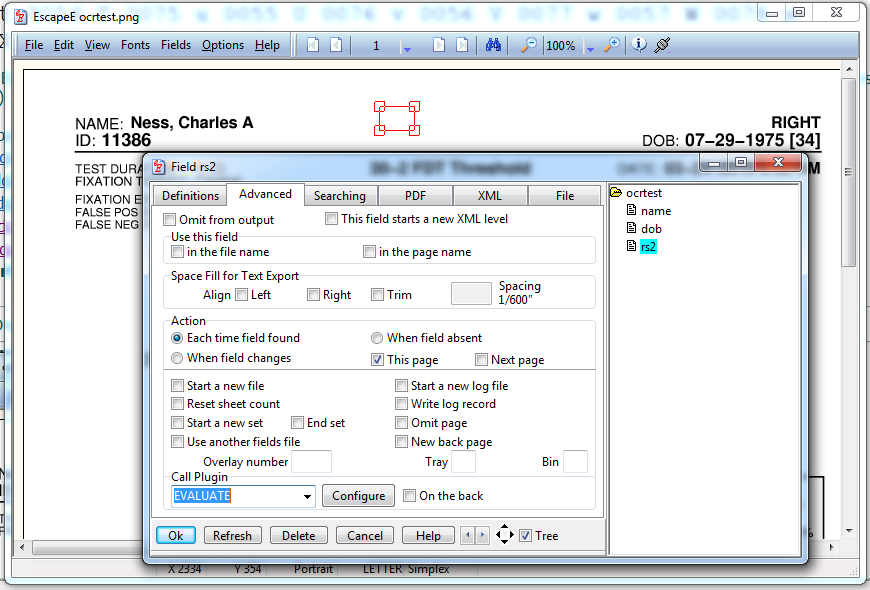
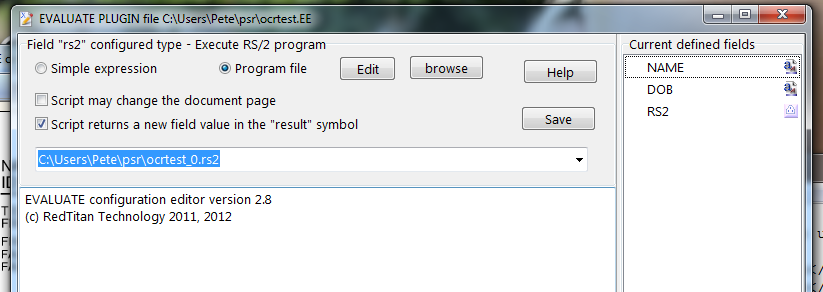
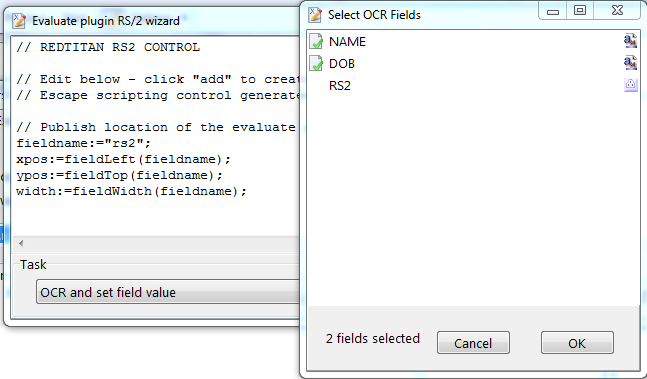
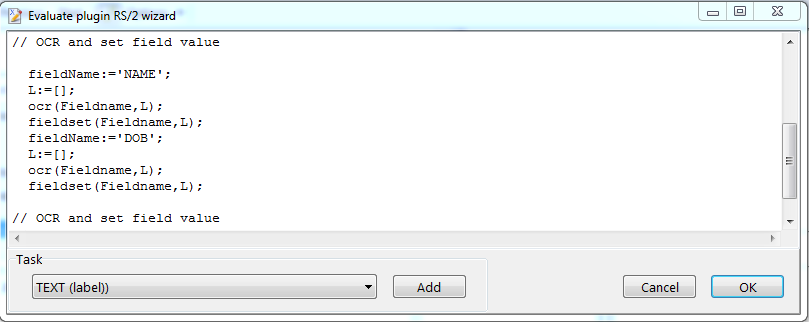
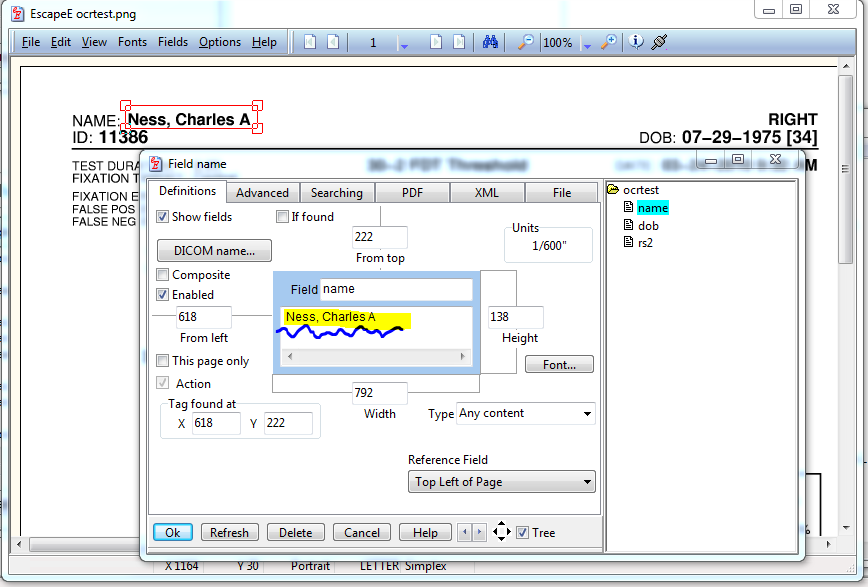
Example RS2 EVALUATE script.
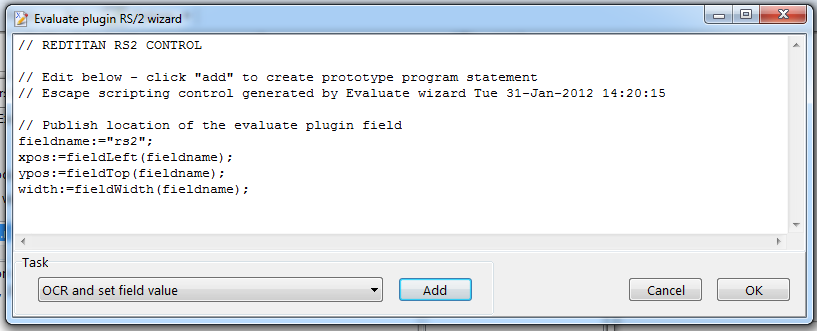
// REDTITAN RS2 CONTROL
L:=[];
ocr('REF',L);
text(10,10,L);
Note 1: The Pascal syntax is extended in RS2 to include a simple list type.
e.g. L:=["lang=deu","whitelist=0123456789,."];
whitelist gives a list of characters that are permitted in the recognition process.